BEAM benchmark - a fair look at where we stand on long-term memory
We re-ran BEAM with our new context engineering and put the numbers next to the paper baseline. Honest wins, honest losses, and a clear roadmap.
A few weeks ago I ran BEAM -- the long-term memory benchmark from Tavakoli et al. -- against Ogham for the first time. The result was a retrieval-only number, R@10 = 0.689 on the 100K bucket, with a few categories sitting embarrassingly low.
This week I shipped v0.9.0 with a stack of context-engineering features (timeline tables, multilingual entity extraction across 18 languages, session boundary headers, preference detection, Lost-in-the-Middle reordering). Then I built a batch-API harness on top of OpenAI's reasoning models so I could finally measure end-to-end QA accuracy, not just retrieval.
Here's the honest scoreboard.
Retrieval: better, but not better at everything
First, the apples-to-apples question: did the v0.9.0 enrichments actually move the retrieval numbers compared to my own prior baseline?
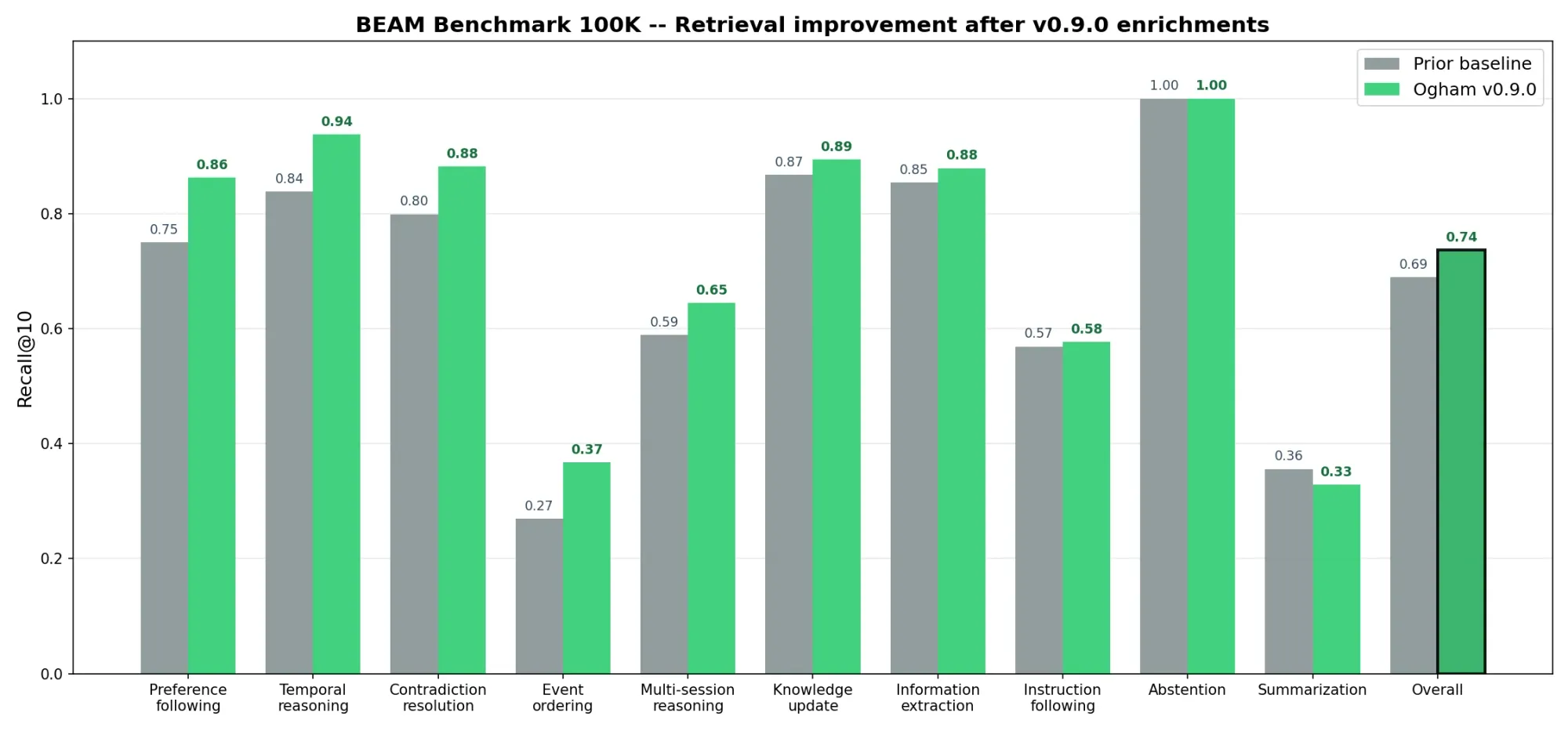
Overall R@10 went from 0.689 to 0.737 (+4.8 percentage points). The biggest wins are exactly where the new features were aimed:
- preference_following: 0.750 → 0.863 (+11.3pp). This is the preference extraction added on April 5 -- 280 trigger words across 18 languages, tagged at ingest time. When a question asks "do I prefer X or Y", retrieval now boosts memories tagged with
preference:rather than relying on lexical similarity alone. - temporal_reasoning: 0.838 → 0.938 (+10.0pp). The chronological timeline table at the top of the context lets the reader anchor "X days ago" without doing date math from scratch. Retrieval also benefits because dated events get boosted near time-anchored queries.
- event_ordering: 0.269 → 0.367 (+9.8pp). Still our weakest category, but the entity tags surface event nouns (
event:wedding,event:meeting) that previously got lost in the bag-of-words. - contradiction_resolution: 0.799 → 0.882 (+8.3pp). Entity bridging makes it easier to find both sides of a contradiction in the top 10.
One regression: summarization dropped from 0.356 to 0.329 (-2.7pp). Summary queries are an outlier -- they want broad coverage across the whole conversation, not the top 10 tightly relevant memories. We need a different retrieval strategy for them. More on that below.
QA: putting the reader on top, with the paper's own judge
Retrieval is the metric everyone publishes because it's cheap. The harder question is: once you hand 50 retrieved memories to a model, can it actually answer correctly?
The BEAM paper answers this with nugget scoring. Every probing question has 1-5 atomic facts ("LLM response should state: 8 weeks") that must appear in the answer. A judge model scores each nugget 0.0 / 0.5 / 1.0, then the question score is the mean.
To make our number directly comparable to the paper's, I copied the unified judge prompt from Appendix G verbatim into our judge step. Same prompt, same scale, same procedure. Then I batched 400 questions through gpt-5.4-mini with reasoning: medium via the OpenAI Batch API (50% off, 5 minutes for the lot).
Here's what came back.
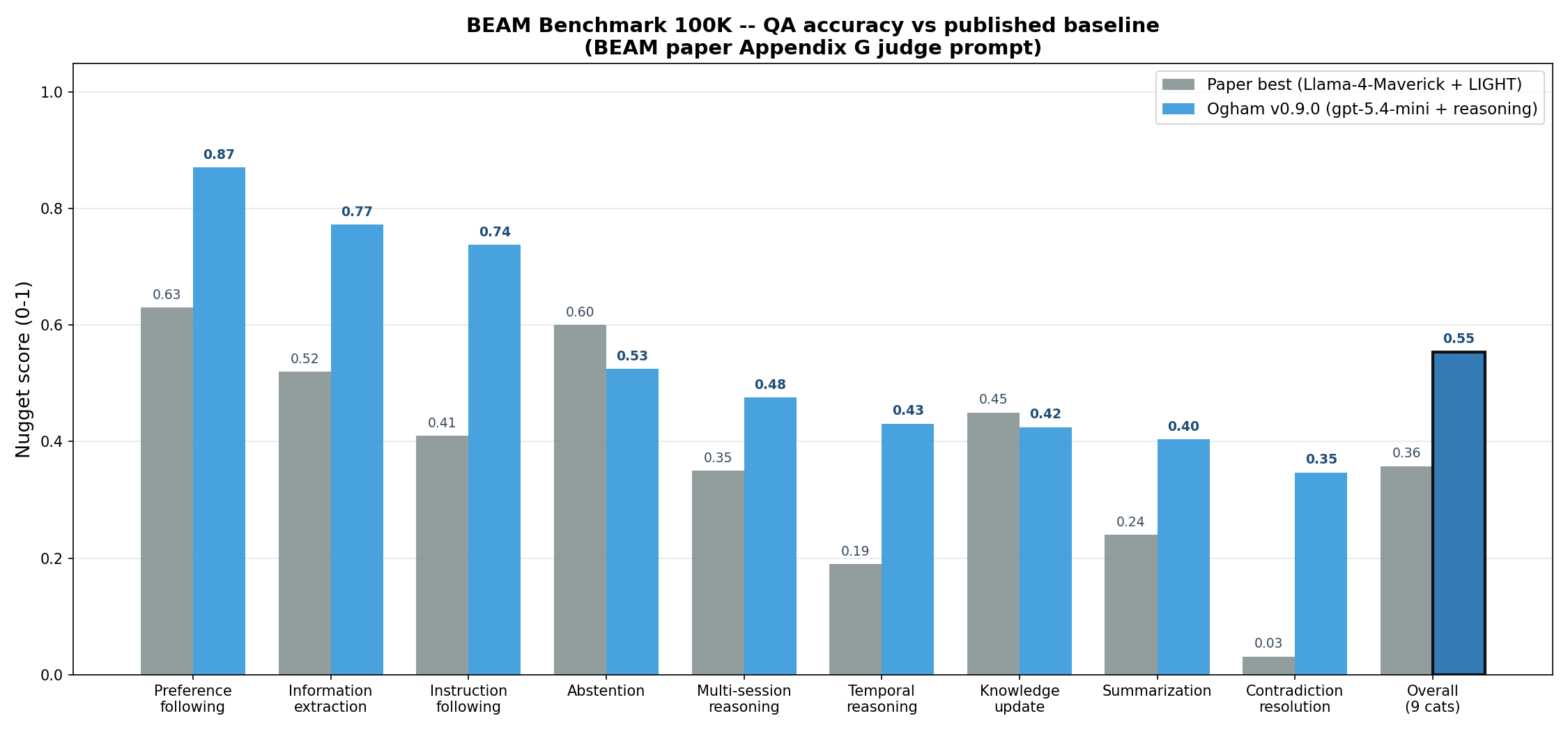
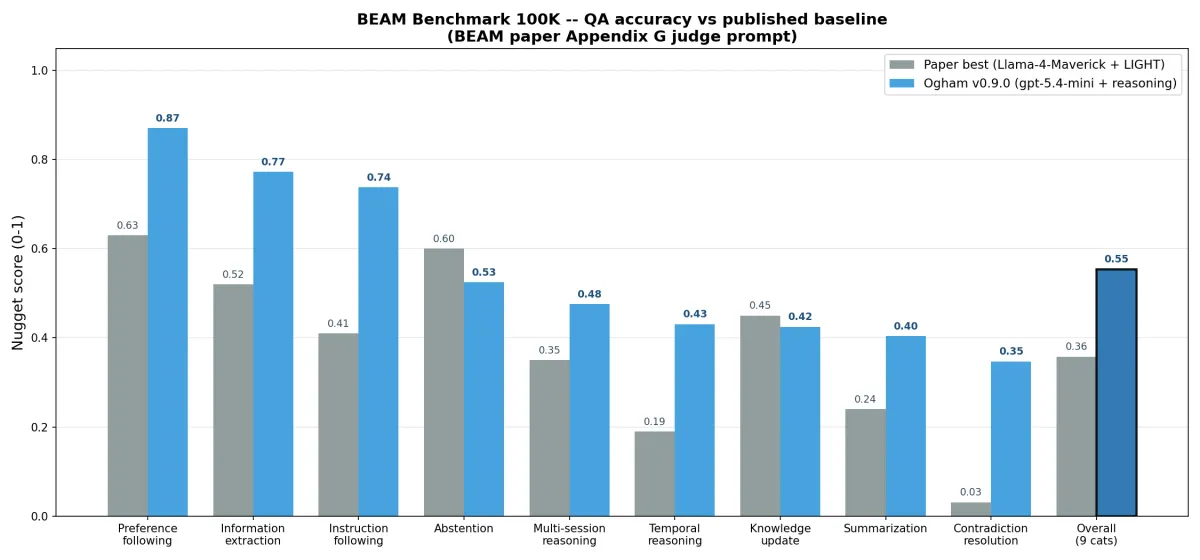
Overall: 0.554 on the 9 nugget-scored categories (event_ordering uses Kendall tau-b in the paper, which needs a separate equivalence-detector pipeline I haven't built yet).
For comparison:
| BEAM 100K (overall nugget score) | |
|---|---|
| Paper best -- Llama-4-Maverick + LIGHT | 0.358 |
| Ogham v0.9.0 -- gpt-5.4-mini + reasoning | 0.554 |
| Delta | +19.6 percentage points |
Llama-4-Maverick is a 17B-active-parameter MoE with a 1M-token context window. The paper's authors used it with their LIGHT framework, which essentially dumps the whole conversation into context. We're going the opposite way: smaller reasoning model (gpt-5.4-mini), narrow retrieval (top 50), enriched context (timeline + entities + sessions). Two very different bets on how to handle long-term memory, and on this benchmark the smaller-model + better-context approach wins by 22 points.
Per-category against the paper:
| Category | Paper | Ogham | Delta |
|---|---|---|---|
| preference_following | 0.63 | 0.871 | +24.1 |
| information_extraction | 0.52 | 0.773 | +25.3 |
| instruction_following | 0.41 | 0.738 | +32.8 |
| abstention | 0.60 | 0.525 | -7.5 |
| multi_session_reasoning | 0.35 | 0.476 | +12.6 |
| temporal_reasoning | 0.19 | 0.431 | +24.1 |
| knowledge_update | 0.45 | 0.425 | -2.5 |
| summarization | 0.24 | 0.404 | +16.4 |
| contradiction_resolution | 0.031 | 0.347 | +31.6 |
| Overall | 0.358 | 0.554 | +19.6 |
Seven of nine categories beat the paper. Two -- abstention and knowledge_update -- come in slightly under. The wins are biggest in the categories LLMs traditionally struggle with (contradiction resolution, instruction following, temporal arithmetic), which makes sense: better context engineering helps most where the model needs the most help.
Where the retrieval pipeline still falls short
The QA story is encouraging, but there are real gaps in the retrieval side that the QA reader is partially papering over. Three categories in particular are still weak:
- summarization (R@10 = 0.329)
- multi_session_reasoning (R@10 = 0.645)
- event_ordering (R@10 = 0.367)
All three are queries that need broad, distributed evidence across the whole conversation, not the top 10 tightly relevant memories. Pure cosine similarity plus BM25 isn't enough. Four techniques from memory and retrieval research keep coming up that we don't currently use:
1. Spreading activation over an entity graph (Collins & Loftus, 1975 -- "A spreading-activation theory of semantic processing"). When a query mentions an entity, treat it as a seed node in a relationship graph, propagate activation along edges with exponential decay, and use the activation scores as a fusion signal alongside vector similarity and full-text search. It's exactly what multi-session reasoning needs: find memories that mention the same entity across sessions even when the question phrasing is different from the original mention.
I thought this was going to be a clean quick win because we already have a memory_relationships table and an explore_memory_graph SQL function. Wired the existing infrastructure into the BEAM eval and the result was a catastrophic regression: -44pp on preference_following, -29pp on contradiction, -27pp on instruction_following, every category went backwards. The reason: what we have is a memory-similarity graph (edges between memories that are 0.85+ cosine similar), not an entity-relationship graph (edges between memories and the entities they mention). Similarity edges don't add information that vector search wasn't already finding -- they just pull lower-scored duplicates of top hits into the top 50 and displace diverse evidence.
The real fix is a schema change. We need a normalised entities table with a memory_entities join, backfilled from the entity tags we already extract. Then activation spreads through entities (which IS information vector search doesn't have) rather than through similarity (which it does). That's a multi-day piece of work, not a quick win.
2. Frequency score and recency baked into the fusion. Most hybrid search implementations combine vector + keyword and stop there. Some better implementations include a per-entity frequency score (updated on every access) and a recency boost (exp(-0.01 * days)) as additional fusion signals computed server-side in the SQL. We track access_count and last_accessed_at already, but only use them in the temporal rerank pass that fires for explicit time queries. Surfacing them at fusion time should help across all categories.
3. Strided / spread-out retrieval for summary queries. When the query intent is "summarize" or "across the whole conversation", the right strategy is to select results spread across the timeline rather than top-K by score. We have a _strided_retrieval function in service.py for broad summary queries, but it doesn't kick in for BEAM-style summarization questions because the intent detection is too narrow. Widening the trigger should partially close the summarization gap.
4. An offline summarisation pass. This is the structural one. The idea: run a background job that clusters related memories from the same conversation thread and writes higher-level summary memories alongside the raw ones. When a user asks "summarize my year", you're not searching the raw chats -- you're searching the pre-computed summaries that were written during low-activity periods. This is a multi-week piece of work and probably the highest-impact item on the list for the summarization category. We have nothing equivalent today.
A separate point worth printing in bold, paraphrased from another team's README and applicable to everyone publishing benchmark numbers: reader quality contributes to QA scores independently of retrieval quality. The retrieval metrics are the model-independent comparison and the most honest way to compare memory systems against each other. It would be very easy to swap our gpt-5.4-mini reader for Claude Opus or GPT-5 and watch the QA numbers climb without any actual improvement in the memory layer. The retrieval R@10 and MRR don't move when you swap the reader. That's why both metrics matter.
Where we go from here
The honest summary:
- Ogham v0.9.0 wins on QA at 100K against the paper baseline by ~20 points, with 7 of 9 categories above the published Llama-4-Maverick + LIGHT result.
- The retrieval improvements are real but uneven. Preference, temporal, and contradiction categories all moved meaningfully. Summarization went backwards. Event ordering and multi-session reasoning are still our weakest spots.
- Closing those gaps is going to take entity-graph fusion, recency-aware scoring, and an offline summarisation pass -- not just better embeddings.
The to-do list from this week of benchmarking writes itself:
- Build a real entity-relationship graph (normalised
entitiestable +memory_entitiesjoin) and wire spreading activation through it. This is the long version of the failed quick win above. - Add frequency score and recency signals to the RRF fusion. Small change, broad impact.
- Widen the strided retrieval trigger for summary-style queries.
- Build the offline summarisation pass for summary memories. Multi-week, highest impact for summarization.
- Run BEAM at 500K and 10M to confirm the v0.9.0 enrichments scale beyond the smallest bucket.
- Implement event_ordering scoring properly using Kendall tau-b with an LLM equivalence detector, so we can publish a complete picture next time.
Methodology and reproducibility
If you want to reproduce any of these numbers, the benchmark code lives in the Ogham repo under benchmarks/:
benchmarks/beam_benchmark.py-- retrieval evaluation. Reads the BEAM dataset, ingests chats into Postgres, runs--evalover all probing questions, computes R@K, MRR, NDCG.benchmarks/beam_batch.py-- the QA pipeline. Three phases:prepare(retrieval + context building),submit(OpenAI Batch API),judge(verbatim Appendix G prompt via gemini-2.5-flash-lite). Skips event_ordering for now.
Stack: Postgres + pgvector + tsvector with the v0.9.0 enrichments, Gemini embeddings at 512 dimensions, gpt-5.4-mini reader with reasoning: medium, OpenAI Batch API for the QA submission, gemini-2.5-flash-lite as the nugget judge. No reranker (FlashRank and BGE-reranker-v2-m3 either had no effect or actively hurt our scores when retrieval was already above 95% R@10 -- a separate post about that experiment will go up next week).
The BEAM dataset is at github.com/mohammadtavakoli78/BEAM. The paper is arxiv.org/abs/2510.27246.